搜索到
252
篇与
的结果
-
 【ThinkPHP】ThinkPHP6处理接口版本问题 'domain_bind' => [ 'api' => 'api', // blog子域名绑定到blog应用 'admin.tp.com' => 'admin', // 完整域名绑定 '*' => 'home', // 二级泛域名绑定到home应用 ], // url版本路由,在url地址上带版本号 Route::rule(':version/:controller/:function', ':version.:controller/:function') ->allowCrossDomain([ 'Access-Control-Allow-Origin' => '*', // //解决跨域问题 'Access-Control-Allow-Methods' => '*', 'Access-Control-Allow-Headers' => '*', 'Access-Control-Request-Headers' => '*' ]); // 头部模式(请求头部带版本号) $version = request()->header('version'); //默认跳转到v1版本 if ($version == null) $version = "v1"; Route::rule(':controller/:function', $version . '.:controller/:function');
【ThinkPHP】ThinkPHP6处理接口版本问题 'domain_bind' => [ 'api' => 'api', // blog子域名绑定到blog应用 'admin.tp.com' => 'admin', // 完整域名绑定 '*' => 'home', // 二级泛域名绑定到home应用 ], // url版本路由,在url地址上带版本号 Route::rule(':version/:controller/:function', ':version.:controller/:function') ->allowCrossDomain([ 'Access-Control-Allow-Origin' => '*', // //解决跨域问题 'Access-Control-Allow-Methods' => '*', 'Access-Control-Allow-Headers' => '*', 'Access-Control-Request-Headers' => '*' ]); // 头部模式(请求头部带版本号) $version = request()->header('version'); //默认跳转到v1版本 if ($version == null) $version = "v1"; Route::rule(':controller/:function', $version . '.:controller/:function'); -
【Layui】Layui事件监听 //监听表单单选框复选框选择 form.on('radio', function (data) { console.log(data.value); //得到被选中的值 }); //监听表单下拉菜单选择 form.on('select', function (data) { console.log(data.value); //得到被选中的值 }); //监听表单复选框选择 form.on('checkbox', function (data) { console.log(data.value); //得到被选中的值 }); //监听表格复选框选择 table.on('checkbox(demo)', function (obj) { console.log(obj); }); //layui监听input内容变动简单粗暴 $(function(){ //输入框的值改变时触发 $("#inputid").on("input",function(e){ //获取input输入的值 console.log(e.delegateTarget.value); }); }); //点击触发监听 $(document).on('click','.class',function(othis){ var data = othis.currentTarget; data.remove(); layer.msg('清除成功'); }); 带注释 form.on('event(过滤器值)', callback); //监听checkbox复选 form.on('checkbox(filter)', function(data){ console.log(data.elem); //得到checkbox原始DOM对象 console.log(data.elem.checked); //是否被选中,true或者false console.log(data.value); //复选框value值,也可以通过data.elem.value得到 console.log(data.othis); //得到美化后的DOM对象 }); //监听switch复选 form.on('switch(filter)', function(data){ console.log(data.elem); //得到checkbox原始DOM对象 console.log(data.elem.checked); //开关是否开启,true或者false console.log(data.value); //开关value值,也可以通过data.elem.value得到 console.log(data.othis); //得到美化后的DOM对象 }); //监听radio单选: form.on('radio(filter)', function(data){ console.log(data.elem); //得到radio原始DOM对象 console.log(data.elem.dataset);//获取dataset参数 console.log(data.value); //被点击的radio的value值 }); //监听submit提交: <button lay-submit lay-filter="*">提交</button> form.on('submit(*)', function(data){ console.log(data.elem) //被执行事件的元素DOM对象,一般为button对象 console.log(data.form) //被执行提交的form对象,一般在存在form标签时才会返回 console.log(data.field) //当前容器的全部表单字段,名值对形式:{name: value} return false; //阻止表单跳转。如果需要表单跳转,去掉这段即可。 }); 监听Select的改变 <!-- 不用form 用div也可以 --> <form class="layui-form"> <div class="layui-form-item"> <label class="layui-form-label">下拉选择框</label> <div class="layui-input-block"> <select name="interest" lay-filter="aihao"> <option value="0">写作</option> <option value="1">阅读</option> <option value="2">听歌</option> <option value="4">游戏</option> </select> </div> </div> </form> <script type="text/javascript" src="./layui/layui.js"></script> <script type="text/javascript"> layui.use('form', function(){ var form = layui.form; form.on('select(aihao)',function(data){ console.log(data); console.log(data.elem); //得到select原始DOM对象 console.log(data.value); //得到被选中的值 console.log(data.othis); //得到美化后的DOM对象 console.log(data.elem.dataset);//获取dataset参数 }); });
-
【Layui】layui自动关闭页面 layui <script> layui.use('layer',function(){ var layer = layui.layer; layer.ready(function(){ layer.msg('操作成功,3秒后会自动关闭当前页面!', {offset: '15px',icon: 1,time: 3000}, function(){ var index = parent.layer.getFrameIndex(window.name); parent.layer.close(index) window.parent.location.reload(); return false; }); }); }); </script> js <div id="box"> <p>页面在 <span id="Os">5</span> s后跳转 </p> </div> <script> var Os=document.getElementById("Os"); var num=5; var timer=setInterval(function () { num--; Os.innerText=num; if(num==0){ window.location.href="https://www.baidu.com/"; } },1000) </script>
-
【Git】error: the requested upstream branch 'origin/master' does not exist 问题:1、本地初始化了git仓库,放了一些文件进去并进行了add操作和commit提交操作;2、github创建了git仓库并建立了README,.gitignore等文件;3、本地仓库添加了github上的git仓库作为远程仓库,起名origin;git remote add origin 远程仓库地址4、本地仓库也远程仓库关联git branch --set-upstream-to=origin/master master解决问题:如果直接pull,就会出现一下错误,refusing to merge unrelated histories 正确姿势:git pull origin master --allow-unrelated-histories 然后本地远程仓库关联git branch --set-upstream-to=origin/master master 总结一下:本地仓库有文件,远程仓库也有文件,正确姿势:1、git remote add origin 远程仓库地址 2、git pull origin master --allow-unrelated-histories 3、git branch --set-upstream-to=origin/master master 4、git push
-
【Git】No tracked branch configured for branch master or the branch doesn't exist. 遇到错误 No tracked branch configured for branch master or the branch doesn't exist. To make your branch track a remote branch call, for example, 以下两条命令搞定 git branch --set-upstream-to=origin/master master git pull origin master --allow-unrelated-histories
-
-
【MySQL】如何用分页来查询 MySQL百万数据 才是最快的 ? 在开发过程中我们经常会使用分页,核心技术是使用limit进行数据的读取,在使用limit进行分页的测试过程中,得到以下数据:select * from news order by id desc limit 0,10 耗时0.003秒 select * from news order by id desc limit 10000,10 耗时0.058秒 select * from news order by id desc limit 100000,10 耗时0.575秒 select * from news order by id desc limit 1000000,10 耗时7.28秒我们惊讶的发现mysql在数据量大的情况下分页起点越大查询速度越慢,100万条起的查询速度已经需要7秒钟。这是一个我们无法接受的数值!改进方案 1select * from news where id > (select id from news order by id desc limit 1000000, 1) order by id desc limit 0,10查询时间 0.365秒,提升效率是非常明显的!!原理是什么呢???我们使用条件对id进行了筛选,在子查询 (select id from news order by id desc limit 1000000, 1) 中我们只查询了id这一个字段比起select * 或 select 多个字段 节省了大量的查询开销!改进方案2 适合id连续的系统,速度极快!select * from news where id between 1000000 and 1000010 order by id desc不适合带有条件的、id不连续的查询。速度非常快!百万数据分页的注意事项 接上一节,我们加上查询条件:select id from news where cate = 1 order by id desc limit 500000 ,10查询时间 20 秒好恐怖的速度!!利用上面方案进行优化:select * from news where cate = 1 and id > (select id from news where cate = 1 order by id desc limit 500000,1 ) order by id desc limit 0,10 查询时间 15 秒优化效果不明显,条件带来的影响还是很大!在这样的情况下无论我们怎么去优化sql语句就无法解决运行效率问题。那么换个思路:建立一个索引表,只记录文章的id、分类信息,我们将文章内容这个大字段分割出去。表 news2 [ 文章表 引擎 myisam 字符集 utf-8 ]id int 11 主键自动增加cate int 11 索引在写入数据时将2张表同步,查询是则可以使用news2 来进行条件查询:select * from news where cate = 1 and id > (select id from news2 where cate = 1 order by id desc limit 500000,1 ) order by id desc limit 0,10注意条件 id > 后面使用了news2 这张表!运行时间 1.23秒,我们可以看到运行时间缩减了近20倍!!数据在10万左右是查询时间可以保持在0.5秒左右,是一个逐步接近我们能够容忍的值!但是1秒对于服务器来说依然是一个不能接受的值!!还有什么可以优化的办法吗??我们尝试了一个伟大的变化:将 news2 的存储引擎改变为innodb,执行结果是惊人的!select * from news where cate = 1 and id > (select id from news2 where cate = 1 order by id desc limit 500000,1 ) order by id desc limit 0,10只需要 0.2秒,非常棒的速度。到了这一步,我们的分页优化完毕,显然是有很大的效果的。你自己可以测试一下!
-
-
【PHP】PHP实现协同推荐算法 概述: 因为最近对算法这块进行了学习,所以最近对类似淘宝商品推荐的协同推荐算法进行了整理总结,本文将用php语言进行实现,文章将从以下几点进行终结: (1)什么是协同推荐算法?有什么用? (2)依据什么数学方法公式,为什么要用它? (3)实现流程是怎样的? (4)具体实现步骤。 首先,第一点,我们要实现一个算法必须要知道它有什么用,核心思想是什么?顾名思义,它的用途就是用来给我们做一些相似性推荐,推荐你喜欢的恭喜,根据你的好友等预测你喜欢的然后再推荐给你;我们举个例子来概括一下算法的核心思想:该算法的核心思想可以概括为:若a,b喜欢同一系列的物品(暂时称b是a的邻居吧),则a很可能喜欢b喜欢的其他物品。算法的实现流程可以简单概括为:1.确定a有哪些邻居 2.通过邻居来预测a可能会喜欢哪种物品 3.将a可能喜欢的物品推荐给a。 现在我们了解了这个核心思想以后,我们知道算法的核心是数学逻辑,我们必须理解其数学思想,然后再转化为编程思想达到我们的目标: 我们先回忆一下余弦定理: 可见cosA的夹角越小cosA的值越大,则边c和边b的长度越相近,因此我们利用余弦定理的向量方式类推出如下公式:1.余弦相似度(求邻居):2.预测公式(预测a可能会喜欢哪种物品): 接下来我们介绍一下实现流程: 现在我们具体看看怎样用php实现这个算法: (1)数据准备:在这里我们直接定义一组数据$userarray= [ ['name'=>'A','a'=>3,'b'=>2,'c'=>1,'d'=>5,'e'=>null,'f'=>null,'g'=>null], ['name'=>'B','a'=>1,'b'=>6,'c'=>6,'d'=>5,'e'=>2,'f'=>3,'g'=>5], ['name'=>'C','a'=>3,'b'=>5,'c'=>null,'d'=>4,'e'=>3,'f'=>3,'g'=>6], ['name'=>'D','a'=>4,'b'=>1,'c'=>1,'d'=>5,'e'=>3,'f'=>3,'g'=>3], ['name'=>'E','a'=>5,'b'=>1,'c'=>null,'d'=>4,'e'=>5,'f'=>1,'g'=>5], ['name'=>'F','a'=>1,'b'=>3,'c'=>2,'d'=>5,'e'=>6,'f'=>null,'g'=>4], ['name'=>'G','a'=>1,'b'=>5,'c'=>2,'d'=>5,'e'=>2,'f'=>3ll,'g'=>5] ]; (2)我们以A用户为对象分别计算出他们的余弦相似度,然后将其存入数组$cos中:/* * 以下示例只求A的推荐 */ $cos = []; $cos[0] = 0; $denominator_left = 0;//分母左边初始值 //开始计算cos //计算分母左边 for($i=1;$i<8;$i++){ if($userarray[0][$i] != null){//$userarray[0]代表A $denominator_left += $userarray[0][$i] * $userarray[0][$i]; } } $denominator_left = sqrt($denominator_left);//取算数平方根的值 for($i=1;$i<6;$i++){ $numerator = 0;//分子初始值 $denominator_right = 0;//分母右边初始值 for($j=1;$j<8;$j++){ //计算分子 if($userarray[0][$j] != null && $userarray[$i][$j] != null){ $numerator += $userarray[0][$j] * $userarray[$i][$j]; } //计算分母右边 if($userarray[$i][$j] != null){ $denominator_right += $userarray[$i][$j] * $userarray[$i][$j]; } } $denominator_right = sqrt($denominator_right ); $cos[$i]['cos'] = $numerator /$denominator_left /$denominator_right ;//存储当前用户的cos近似值 $cos[$i]['name'] = $userarray[$i]['name'];//存储当前用户的名字 $cos[$i]['e'] = $userarray[$i]['e'];//存储当前用户的e物品评分 $cos[$i]['f'] = $userarray[$i]['f'];//存储当前用户的f物品评分 $cos[$i]['g'] = $userarray[$i]['g'];//存储当前用户的g物品评分 }(3)我们对余弦近似值进行由大到小的排序,抽取前三个用户作为A用户的邻居,我们使用冒泡排序法对其进行排序// 第一层可以理解为从数组中键为0开始循环到最后一个 for ($i = 0; $i < count($cos) ; $i++) { // 第二层为从$i+1的地方循环到数组最后 for ($j = $i+1; $j < count($cos); $j++) { // 比较数组中两个相邻值的大小 if ($cos[$i]['cos'] < $cos[$j]['cos']) { $tem = $cos[$i]; // 这里临时变量,存贮$i的值 $cos[$i] = $cos[$j]; // 第一次更换位置 $cos[$j] = $tem; // 完成位置互换 } } } (4)接下来我们对A用户可能喜欢的物品进行预测,利用第二个公式,求出product值//计算A对e的评分 $numerator= 0;//分子初始值 $denominator= 0;//分母初始值 for($i=0;$i<3;$i++){ $numerator+= $cos[$i]['cos'] * $cos[$i]['e']; $denominator+= $cos[$i]['cos']; } $score_e = $numerator/sqrt($denominator); //计算A对f的评分 $numerator= 0;//分子初始值 $denominator= 0;//分母初始值 for($i=0;$i<3;$i++){ $numerator+= $cos[$i]['cos'] * $cos[$i]['f']; $denominator+= $cos[$i]['cos']; } $score_f= $numerator/sqrt($denominator); //计算A对g的评分 $numerator= 0;//分子初始值 $denominator= 0;//分母初始值 for($i=0;$i<3;$i++){ $numerator+= $cos[$i]['cos'] * $cos[$i]['g']; $denominator+= $cos[$i]['cos']; } $score_g= $numerator/sqrt($denominator);最后我们可以比较这些值,可以选取值最大的物品推荐给用户A
-
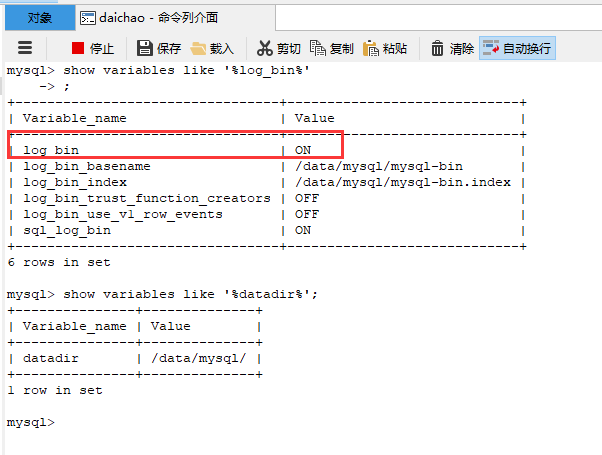
【MySQL】MySQL数据恢复 第一步:保证mysql已经开启binlog,查看命令:查看binklog是否开启 show variables like '%log_bin%'; 查看binlog存放日志文件目录(如下图,博主binlog目录为/data/mysql): show variables like '%datadir%'; 值为OFF,需开启,值为ON,已开启。如果没有开启binlog,也没有预先生成回滚SQL,那可能真的无法快速回滚了。对存放重要业务数据的MySQL,强烈建议开启binlog。第二步:进入binlog文件目录,找出日志文件第三步:切换到mysqlbinlog目录(当线上数据出现错误的时候首先可以询问具体操作人记录时间点,这个时候可以借助mysql自带的binlog解析工具mysqlbinlog,具体位置在mysql安装目录**/mysql/bin/下)第四步:通过mysqlbinlog工具命令查看数据库增删改查记录(必须切换到mysqlbinlog目录才有效)例子1:查询2018-11-12 09:00:00到2018-11-13 20:00:00 数据库为 youxi 的操作日志,输入如下命令将数据写入到一个备用的txt文件中mysqlbinlog --no-defaults --database=youxi --start-datetime="2018-11-12 09:00:00" --stop-datetime="2018-11-13 20:00:00" /data/mysql/mysql-bin.000015 > template_coupon_tb_product_category.txt例子2:查询2018-11-12 09:00:00到2018-11-13 20:00:00 数据库为 youxi 的操作日志,并输出到屏幕上mysqlbinlog --no-defaults --database=youxi --start-datetime="2018-11-12 09:00:00" --stop-datetime="2018-11-13 20:00:00" /data/mysql/mysql-bin.000015 |more例子3:查询2018-11-12 09:00:00到2018-11-13 20:00:00 数据库为 youxi 的操作日志,并且过滤出 只包括 template_coupon_tb_product_category 表数据的操作记录 ,输入如下命令将数据写入到一个备用的txt文件中mysqlbinlog --no-defaults --database=youxi --start-datetime="2018-11-12 09:00:00" --stop-datetime="2018-11-13 20:00:00" /data/mysql/mysql-bin.000015 | grep template_coupon_tb_product_category > template_coupon_tb_product_category.txtmysqlbinlog 命令的语法格式: mysqlbinlog mysql-bin.0000xx | mysql -u用户名 -p密码 数据库名 -------------------------------------------------------- 常用参数选项解释: --start-position=875 起始pos点 --stop-position=954 结束pos点 --start-datetime="2016-9-25 22:01:08" 起始时间点 --stop-datetime="2019-9-25 22:09:46" 结束时间点 --database=zyyshop 指定只恢复zyyshop数据库(一台主机上往往有多个数据库,只限本地log日志) -------------------------------------------------------- 不常用选项: -u --user=name 连接到远程主机的用户名 -p --password[=name] 连接到远程主机的密码 -h --host=name 从远程主机上获取binlog日志 --read-from-remote-server 从某个MySQL服务器上读取binlog日志第五步:利用第四步输出的sql语句或者txt文本进行语句过滤,重新插入数据或更新数据
-
【PHP】PHP错误级别 在php编程过程中,大家一定会遇到或多或少的错误提醒,也正是这些错误提示,指引我们编写更加干净的代码,今天先写出我们主要列出的错误类型,先挖坑,写关于php错误与异常的相关知识,慢慢填坑。Deprecated最低级别错误,程序继续执行Notice 通知级别的错误 如直接使用未声明变量,程序继续执行 Warning 警告级别的错误,可能得不到想要的结果 Fatal error 致命级别错误致命级别错误,程序不往下执行 parse error 语法解析错误,最高级别错误,连其他错误信息也不呈现出来 E_USER_相关错误 用户设置的相关错误利用trigger_error()函数设置一个用户级别的 error/warning/notice 信息如何设置错误级别? error_reporting(-1)显示所有错误,error_reporting(0)屏蔽所有错误。ini_set('error_reporting',0)也是屏蔽所有错误。可以在php.ini文件中设置error_reporting来使脚本显示或不显示某些错误。ini_set('display_errors','On')显示错误。 注意:error_reporting()设置报告何种错误,而ini_set('display_errors','On')设置是否在输出错误。因而error_reporting(-1)和ini_set('display_errors',0)可用作设置日志:报告错误并且不输出。 举例:error_reporting(E_ALL&~E_NOTICE)不显示通知级别的错误。“~”表示非。
-
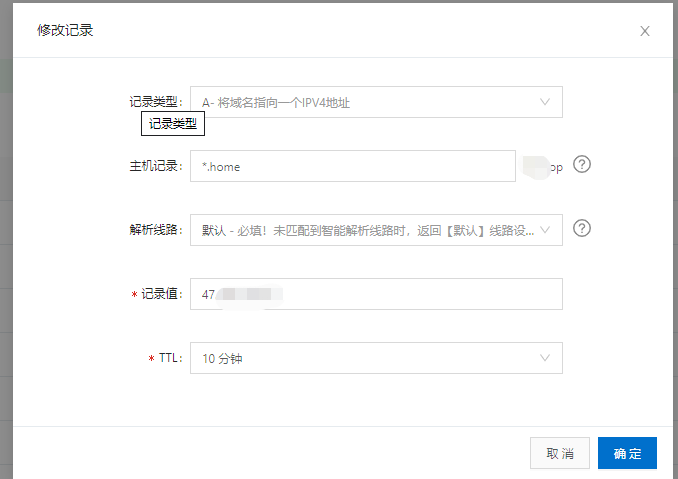
【Nginx】Nginx泛解析配置-站群推广 通常情况下,我们新建一个二级域名都需要去域名提供商的控制面板新建记录,比如我现在有个baidu.com的域名,但是我有好几家分公司,分别是1.baidu.com,2.baidu.com,3.baidu.com。。。。这样就需要建很多二级域名,显然很麻烦,我们只需要在控制台建一个解析记录,使用*就行,如下图新建解析记录然后nginx的配置如下server { listen 80; # 这是你的域名 server_name *.home.baidu.top; location / { # 泛域名开始配置 if ( $host ~* (.*)\.(.*)\.(.*)\.(.*) ) { set $domain $1; #获取当前的 域名前缀 } # 这里的domain就是获取当前域名前缀,然后指向到该前缀名称的目录 root /home/customerpage/$domain; index index.html index.htm; } }看到如上配置我是指定到我/home/customerpage/目录下的如图下面新建两个子目录每个目录里都有一个html页面然后我就需要这样访问第一个 和文件名一样 hejie.home.baidu.tophttps://www.cnblogs.com/hjieone/p/12323405.html
-
【PHP】PHPEmail的使用 第一步:使用composer安装phpmailercomposer require phpmailer/phpmailer第二步:common.php写个发送邮件的函数(腾讯邮箱的为例)/** * 系统邮件发送函数 * @param string $tomail 接收邮件者邮箱 * @param string $name 接收邮件者名称 * @param string $subject 邮件主题 * @param string $body 邮件内容 * @param string $attachment 附件列表 * @return boolean * @author static7 <static7@qq.com> */ function send_mail($tomail, $name, $subject = '', $body = '', $attachment = null) { $mail = new \PHPMailer(); //实例化PHPMailer对象 $mail->CharSet = 'UTF-8'; //设定邮件编码,默认ISO-8859-1,如果发中文此项必须设置,否则乱码 $mail->IsSMTP(); // 设定使用SMTP服务 $mail->SMTPDebug = 0; // SMTP调试功能 0=关闭 1 = 错误和消息 2 = 消息 $mail->SMTPAuth = true; // 启用 SMTP 验证功能 $mail->SMTPSecure = 'ssl'; // 使用安全协议 $mail->Host = "smtp.exmail.qq.com"; // SMTP 服务器 $mail->Port = 465; // SMTP服务器的端口号 $mail->Username = "static7@qq.com"; // SMTP服务器用户名 $mail->Password = ""; // SMTP服务器密码 $mail->SetFrom('static7@qq.com', 'static7'); $replyEmail = ''; //留空则为发件人EMAIL $replyName = ''; //回复名称(留空则为发件人名称) $mail->AddReplyTo($replyEmail, $replyName); $mail->Subject = $subject; $mail->MsgHTML($body); $mail->AddAddress($tomail, $name); if (is_array($attachment)) { // 添加附件 foreach ($attachment as $file) { is_file($file) && $mail->AddAttachment($file); } } return $mail->Send() ? true : $mail->ErrorInfo; }第三步:控制器方法里写发送的内容/** * tp5邮件 * @param * @author staitc7 <static7@qq.com> * @return mixed */ public function email() { $toemail='static7@qq.com'; $name='static7'; $subject='QQ邮件发送测试'; $content='恭喜你,邮件测试成功。'; dump(send_mail($toemail,$name,$subject,$content)); }第4步:测试发送请自行测试转发:https://www.thinkphp.cn/topic/44477.html
-
【设计模式】装饰器模式 使用场景: 当某一功能或方法draw,要满足不同的功能需求时,可以使用装饰器模式;实现方式:在方法的类中建addDecorator(添加装饰器),beforeDraw,afterDraw 3个新方法, 后2个分别放置在要修改的方法draw首尾.然后创建不同的装器类(其中要包含相同的,beforeDraw,afterDraw方法)能过addDecorator添加进去,然后在beforeDraw,afterDraw中循环处理,与观察者模式使用有点相似1.装饰器模式(Decorator),可以动态地添加修改类的功能2.一个类提供了一项功能,如果要在修改并添加额外的功能,传统的编程模式,需要写一个子类继承它,并重新实现类的方法3.使用装饰器模式,仅需在运行时添加一个装饰器对象即可实现,可以实现最大的灵活性DrawDecorator.php <?php namespace IMooc; interface DrawDecorator { function beforeDraw(); function afterDraw(); } Canvas.php<?php namespace IMooc; class Canvas { public $data; protected $decorators = array(); //Decorator function init($width = 20, $height = 10) { $data = array(); for($i = 0; $i < $height; $i++) { for($j = 0; $j < $width; $j++) { $data[$i][$j] = '*'; } } $this->data = $data; } function addDecorator(DrawDecorator $decorator) { $this->decorators[] = $decorator; } function beforeDraw() { foreach($this->decorators as $decorator) { $decorator->beforeDraw(); } } function afterDraw() { $decorators = array_reverse($this->decorators); foreach($decorators as $decorator) { $decorator->afterDraw(); } } function draw() { $this->beforeDraw(); foreach($this->data as $line) { foreach($line as $char) { echo $char; } echo "<br />\n"; } $this->afterDraw(); } function rect($a1, $a2, $b1, $b2) { foreach($this->data as $k1 => $line) { if ($k1 < $a1 or $k1 > $a2) continue; foreach($line as $k2 => $char) { if ($k2 < $b1 or $k2 > $b2) continue; $this->data[$k1][$k2] = ' '; } } } } ColorDrawDecorator.php<?php namespace IMooc; class ColorDrawDecorator implements DrawDecorator { protected $color; function __construct($color = 'red') { $this->color = $color; } function beforeDraw() { echo "<div style='color: {$this->color};'>"; } function afterDraw() { echo "</div>"; } } index.php<?php define('BASEDIR', __DIR__); include BASEDIR.'/IMooc/Loader.php'; spl_autoload_register('\\IMooc\\Loader::autoload'); $canvas = new IMooc\Canvas(); $canvas->init(); $canvas->addDecorator(new \IMooc\ColorDrawDecorator('green')); $canvas->rect(3,6,4,12); $canvas->draw();
-
【设计模式】策略模式 将一组特定的行为和算法封装成类,以适应某些特定的上下文环境。使用场景: 个人理解,策略模式是依赖注入,控制反转的基础例如:一个电商网站系统,针对男性女性用户要各自跳转到不同的商品类目,并且所有广告位展示不同的广告MaleUserStrategy.php<?php namespace IMooc; class MaleUserStrategy implements UserStrategy { function showAd() { echo "IPhone6"; } function showCategory() { echo "电子产品"; } } FemaleUserStrategy.php<?php namespace IMooc; class FemaleUserStrategy implements UserStrategy { function showAd() { echo "2014新款女装"; } function showCategory() { echo "女装"; } } UserStrategy.php<?php namespace IMooc; interface UserStrategy { function showAd(); function showCategory(); } <?php interface FlyBehavior{ public function fly(); } class FlyWithWings implements FlyBehavior{ public function fly(){ echo "Fly With Wings \n"; } } class FlyWithNo implements FlyBehavior{ public function fly(){ echo "Fly With No Wings \n"; } } class Duck{ private $_flyBehavior; public function performFly(){ $this->_flyBehavior->fly(); } public function setFlyBehavior(FlyBehavior $behavior){ $this->_flyBehavior = $behavior; } } class RubberDuck extends Duck{ } // Test Case $duck = new RubberDuck(); /* 想让鸭子用翅膀飞行 */ $duck->setFlyBehavior(new FlyWithWings()); $duck->performFly(); /* 想让鸭子不用翅膀飞行 */ $duck->setFlyBehavior(new FlyWithNo()); $duck->performFly();
-
【设计模式】适配器模式 将一个类的接口转换成客户希望的另一个接口,适配器模式使得原本的由于接口不兼容而不能一起工作的那些类可以一起工作。应用场景: 老代码接口不适应新的接口需求,或者代码很多很乱不便于继续修改,或者使用第三方类库。例如:php连接数据库的方法:mysql,,mysqli,pdo,可以用适配器统一//老的代码 class User { private $name; function __construct($name) { $this->name = $name; } public function getName() { return $this->name; } } //新代码,开放平台标准接口 interface UserInterface { function getUserName(); } class UserInfo implements UserInterface { protected $user; function __construct($user) { $this->user = $user; } public function getUserName() { return $this->user->getName(); } } $olduser = new User('张三'); echo $olduser->getName()."n"; $newuser = new UserInfo($olduser); echo $newuser->getUserName()."n";
-
【设计模式】观察者设计模式 观察者模式是挺常见的一种设计模式,使用得当会给程序带来非常大的便利,使用得不当,会给后来人一种难以维护的想法。使用场景: 用户登录,需要写日志,送积分,参与活动 等使用消息队列,把用户和日志,积分,活动之间解耦合什么是观察者模式? 一个对象通过提供方法允许另一个对象即观察者 注册自己)使本身变得可观察。当可观察的对象更改时,它会将消息发送到已注册的观察者。这些观察者使用该信息执行的操作与可观察的对象无关。结果是对象可以相互对话,而不必了解原因。观察者模式是一种事件系统,意味着这一模式允许某个类观察另一个类的状态,当被观察的类状态发生改变的时候,观察类可以收到通知并且做出相应的动作;观察者模式为您提供了避免组件之间紧密耦。看下面例子你就明白了!<?php /* 观察者接口 */ interface InterfaceObserver { function onListen($sender, $args); function getObserverName(); } // 可被观察者接口 interface InterfaceObservable { function addObserver($observer); function removeObserver($observer_name); } // 观察者抽象类 abstract class Observer implements InterfaceObserver { protected $observer_name; function getObserverName() { return $this->observer_name; } function onListen($sender, $args) { } } // 可被观察类 abstract class Observable implements InterfaceObservable { protected $observers = array(); public function addObserver($observer) { if ($observerinstanceofInterfaceObserver) { $this->observers[] = $observer; } } public function removeObserver($observer_name) { foreach ($this->observersas $index => $observer) { if ($observer->getObserverName() === $observer_name) { array_splice($this->observers, $index, 1); return; } } } } // 模拟一个可以被观察的类 class A extends Observable { public function addListener($listener) { foreach ($this->observersas $observer) { $observer->onListen($this, $listener); } } } // 模拟一个观察者类 class B extends Observer { protected $observer_name = 'B'; public function onListen($sender, $args) { var_dump($sender); echo "<br>"; var_dump($args); echo "<br>"; } } // 模拟另外一个观察者类 class C extends Observer { protected $observer_name = 'C'; public function onListen($sender, $args) { var_dump($sender); echo "<br>"; var_dump($args); echo "<br>"; } } $a = new A(); // 注入观察者 $a->addObserver(new B()); $a->addObserver(new C()); // 可以看到观察到的信息 $a->addListener('D'); // 移除观察者 $a->removeObserver('B'); // 打印的信息: // object(A)#1 (1) { ["observers":protected]=> array(2) { [0]=> object(B)#2 (1) { ["observer_name":protected]=> string(1) "B" } [1]=> object(C)#3 (1) { ["observer_name":protected]=> string(1) "C" } } } // string(1) "D" // object(A)#1 (1) { ["observers":protected]=> array(2) { [0]=> object(B)#2 (1) { ["observer_name":protected]=> string(1) "B" } [1]=> object(C)#3 (1) { ["observer_name":protected]=> string(1) "C" } } } // string(1) "D"
-
【设计模式】工厂设计模式 要是当操作类的参数变化时,只用改相应的工厂类就可以工厂设计模式常用于根据输入参数的不同或者应用程序配置的不同来创建一种专门用来实例化并返回其对应的类的实例。使用场景 :使用方法 new实例化类,每次实例化只需调用工厂类中的方法实例化即可。优点 :由于一个类可能会在很多地方被实例化。当类名或参数发生变化时,工厂模式可简单快捷的在工厂类下的方法中 一次性修改,避免了一个个的去修改实例化的对象。我们举例子,假设矩形、圆都有同样的一个方法,那么我们用基类提供的API来创建实例时,通过传参数来自动创建对应的类的实例,他们都有获取周长和面积的功能。例子<?php interface InterfaceShape { function getArea(); function getCircumference(); } /** * 矩形 */ class Rectangle implements InterfaceShape { private $width; private $height; public function __construct($width, $height) { $this->width = $width; $this->height = $height; } public function getArea() { return $this->width* $this->height; } public function getCircumference() { return 2 * $this->width + 2 * $this->height; } } /** * 圆形 */ class Circle implements InterfaceShape { private $radius; function __construct($radius) { $this->radius = $radius; } public function getArea() { return M_PI * pow($this->radius, 2); } public function getCircumference() { return 2 * M_PI * $this->radius; } } /** * 形状工厂类 */ class FactoryShape { public static function create() { switch (func_num_args()) { case1: return newCircle(func_get_arg(0)); case2: return newRectangle(func_get_arg(0), func_get_arg(1)); default: # code... break; } } } $rect =FactoryShape::create(5, 5); // object(Rectangle)#1 (2) { ["width":"Rectangle":private]=> int(5) ["height":"Rectangle":private]=> int(5) } var_dump($rect); echo "<br>"; // object(Circle)#2 (1) { ["radius":"Circle":private]=> int(4) } $circle =FactoryShape::create(4); var_dump($circle);
-
【设计模式】单例设计模式(Singleton) 所谓单例模式,即在应用程序中最多只有该类的一个实例存在,一旦创建,就会一直存在于内存中!应用场景: 单例设计模式常应用于数据库类设计,采用单例模式,只连接一次数据库,防止打开多个数据库连接。一个单例类应具备以下特点: 单例类不能直接实例化创建,而是只能由类本身实例化。因此,要获得这样的限制效果,构造函数必须标记为private,从而防止类被实例化。需要一个私有静态成员变量来保存类实例和公开一个能访问到实例的公开静态方法。在PHP中,为了防止他人对单例类实例克隆,通常还为其提供一个空的私有__clone()方法。单例模式的例子:<?php /** * Singleton of Database */ class Database { // We need a static private variable to store a Database instance. privatestatic $instance; // Mark as private to prevent it from being instanced. private function__construct() { // Do nothing. } private function__clone() { // Do nothing. } public static function getInstance() { if (!(self::$instance instanceof self)) { self::$instance = new self(); } return self::$instance; } } $a =Database::getInstance(); $b =Database::getInstance(); // true var_dump($a === $b);
-